NVIDIA A100 Tensor Core GPU
The video version of this post is avaiable here.
We are glad to announce that, with generous funding support from the department, SCRP now offers access to NVIDIA A100 datacenter GPUs for faculty members, research staff and research postgraduate students.
As one of the fastest general-purpose accelerators, the main advantages of the A100 GPU are memory and computational speed. Before having A100s, SCRP offer two types of consumer-grade GPUs: the top-of-the-line RTX 3090 and the mainstream RTX 3060. The RTX 3090 has 24 gigabytes of memory, while the RTX 3060 has half of that. The A100, in contrast, has 80 gigabytes of memory, allowing you to load much larger model or more data.
| GPU | VRAM | FP16* | FP32* | FP64* |
|---|---|---|---|---|
| RTX 3090 | 24GB | 36 | 36 | 0.6 |
| RTX 3060 | 12GB | 13 | 13 | 0.2 |
| A100 | 80GB | 78 | 20 | 9.7 |
*Measure: TFLOPS
When it comes to speed, both the RTX 3090 and RTX 3060 excel in single and half precision computation. The A100 is, however, even faster. This is particularly true in for double-precision computation, which is often necessary for scientific computation. In this specific area, the A100 is over 15-times faster than the RTX 3090. For reference, by default, Stata works in single precision while MATLAB and R work in double precision.
If your computation is heavy on matrix multiplication, the tensor core performance is the more relevant metric. Tensor cores are compute units dedicated to matrix multiplication, providing several times the performance over other operations. Here, once again, the A100 is much faster than the other options. It is worth noting that a single A100 is faster than the fastest supercomputer in the world from 20 years ago.
| GPU | Tensor FP16* | Tensor FP32* |
|---|---|---|
| RTX 3090 | 142 | 36 |
| RTX 3060 | 51 | 13 |
| A100 | 312 | 156 |
Finally, the A100 has many times the inter-GPU bandwidth than the other options, which could be an important consideration if your computation requires the use of multiple GPUs.
| GPU | Inter-GPU Bandwidth |
|---|---|
| RTX 3090 | 113GB/s |
| RTX 3060 | 64GB/s |
| A100 | 600GB/s |
Benchmarks
To see how fast the A100 really are, I will now run through several scenarios. The numbers reported below are in seconds, averaged over three runs.
-
The first scenario simulates a situation where you pass data to the GPU for computation. We first generate a 20K x 20K with CPU, pass it to a GPU, perform two sets of matrix multiplications and then sum the results.
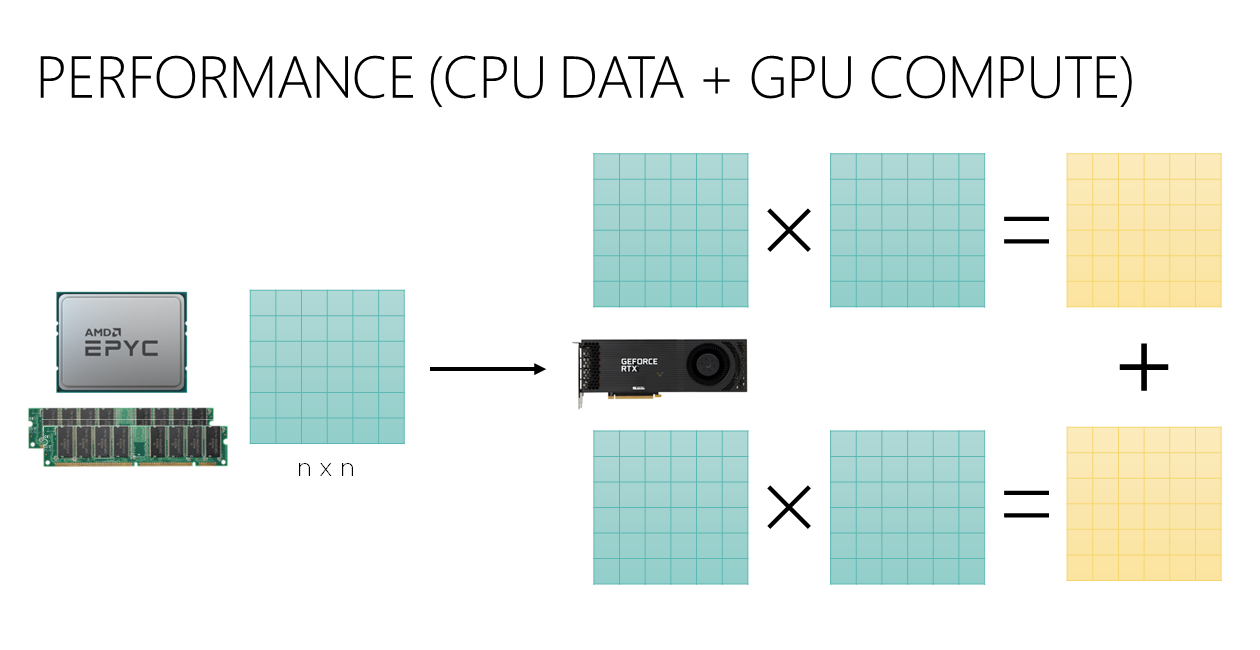
Device FP16^ FP32^ FP64^ Ryzen 5950X - 23.2 53.4 RTX 3090 1.1 1.6 59.5 A100 0.9 1.1 3.7 ^Measure: seconds
Using a GPU is generally much faster than CPU, but the numeric precision you use is going to have a big impact. If you need double precision, only the A100 is going accelerate your computation.
-
Next, we will spread the two matrix multiplications over two GPUs.
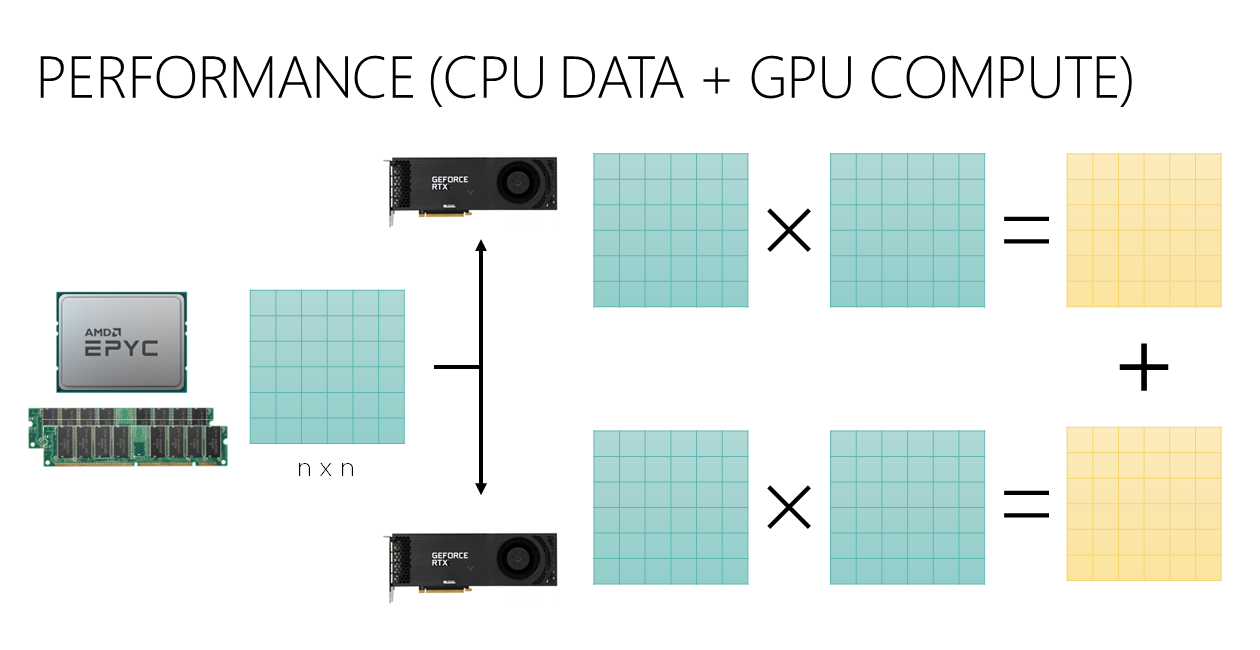
Device FP16^ FP32^ FP64^ RTX 3090 1.3 1.6 31.6 A100 1.4 1.3 3.3 Will this result in faster speed? Perhaps surprisingly, this is only true for double-precision computation. The reason is that computation is bottlenecked by the time it takes for data to transfer from main memory to GPUs.
-
With that in mind, we will try generating the data on GPU instead, followed by the same computation.
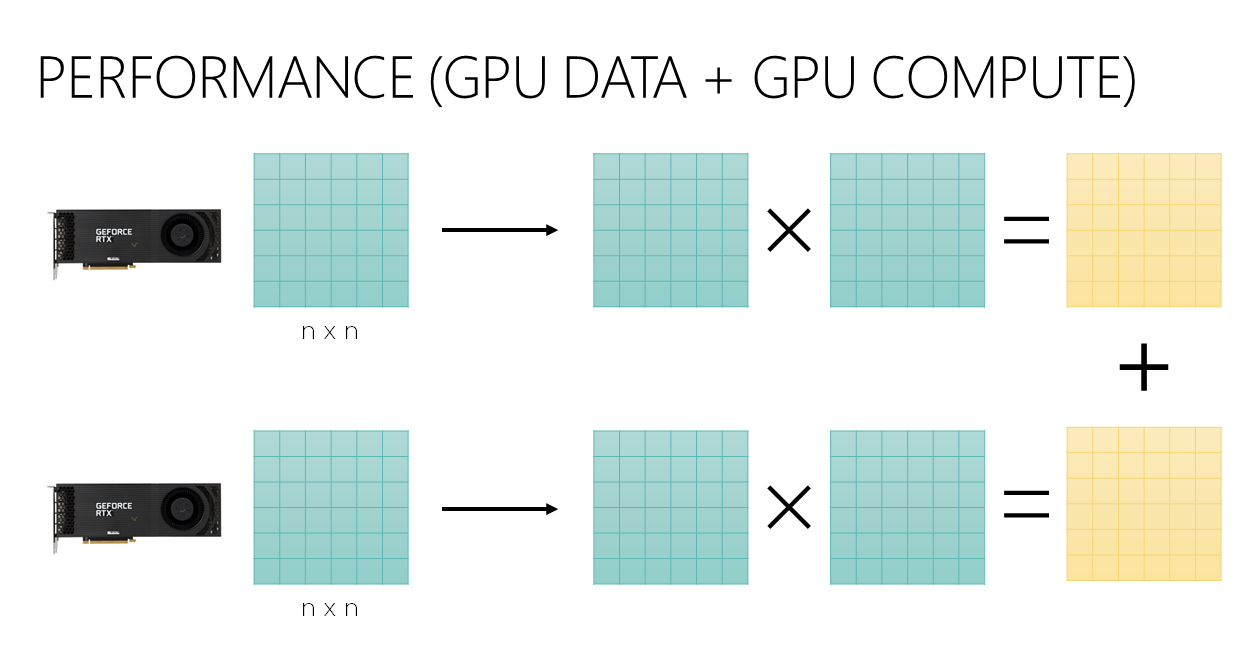
Device FP16^ FP32^ FP64^ RTX 3090 0.23 0.5 29.6 A100 0.1 0.2 1.0 Moving data away from the CPU and main memory result in significantly faster speed. What takes 23 seconds on a modern 16-core CPU only takes 200 milliseconds on an A100.
We therefore have three observations:
- For low-precision computation, any GPU is fine.
- For high-precision computation, you need the A100.
- CPU-to-GPU data transfer is a major bottleneck, so it should be avoided as much as possible.
Finally, I would like to present some benchmarks on deep learning performance of the A100:
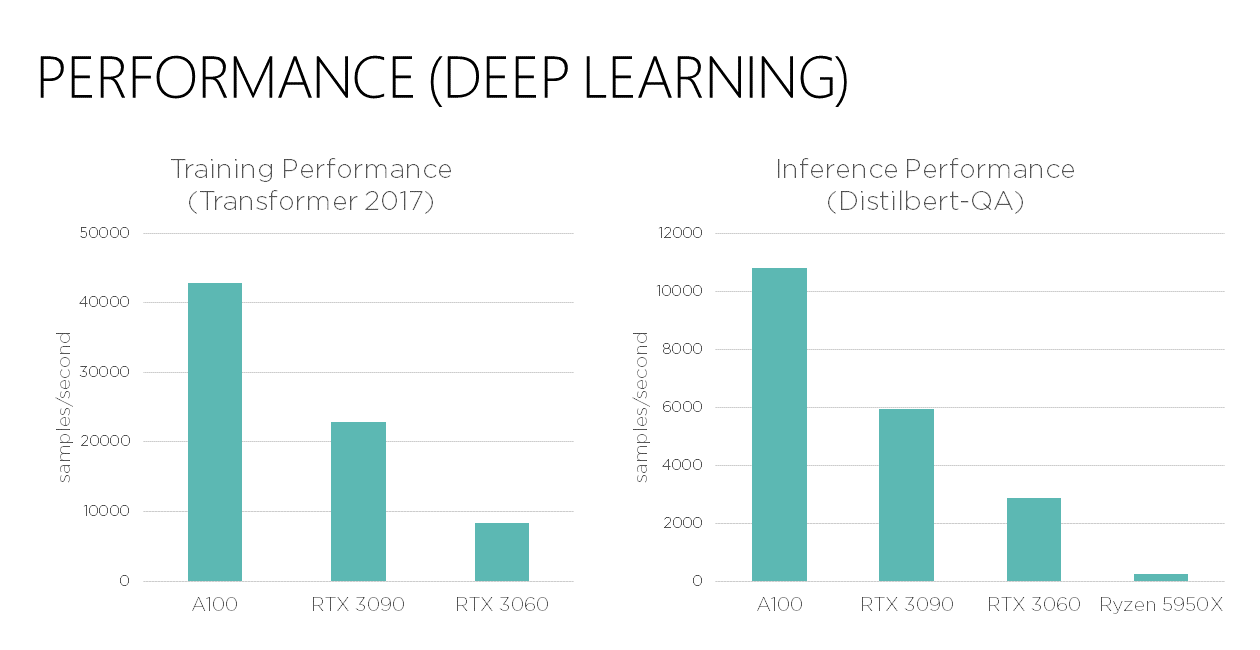
For both training and inference, you can expect around 80% speed up over RTX 3090, due to a combination of more memory and faster computation.
Requesting A100 GPUs
The two A100 GPUs are installed in the new scrp-node-10 compute node.
To request them with the compute command, specify --gpus-per-task=a100[:num].
For example:
compute --gpus-per-task=a100:2 python
will request both A100s. The compute command automatically allocates 8 CPU cores and 160GB RAM per A100.
If you use srun, you need to specify the a100 partition, plus your desired number of CPU cores and memory:
srun -p a100 --gpus-per-task=1 -c 16 --mem=160G [command]
Finally, you can request A100s on JupyterHub (Slurm) for up to three hours.